
Selected
* equal contribution
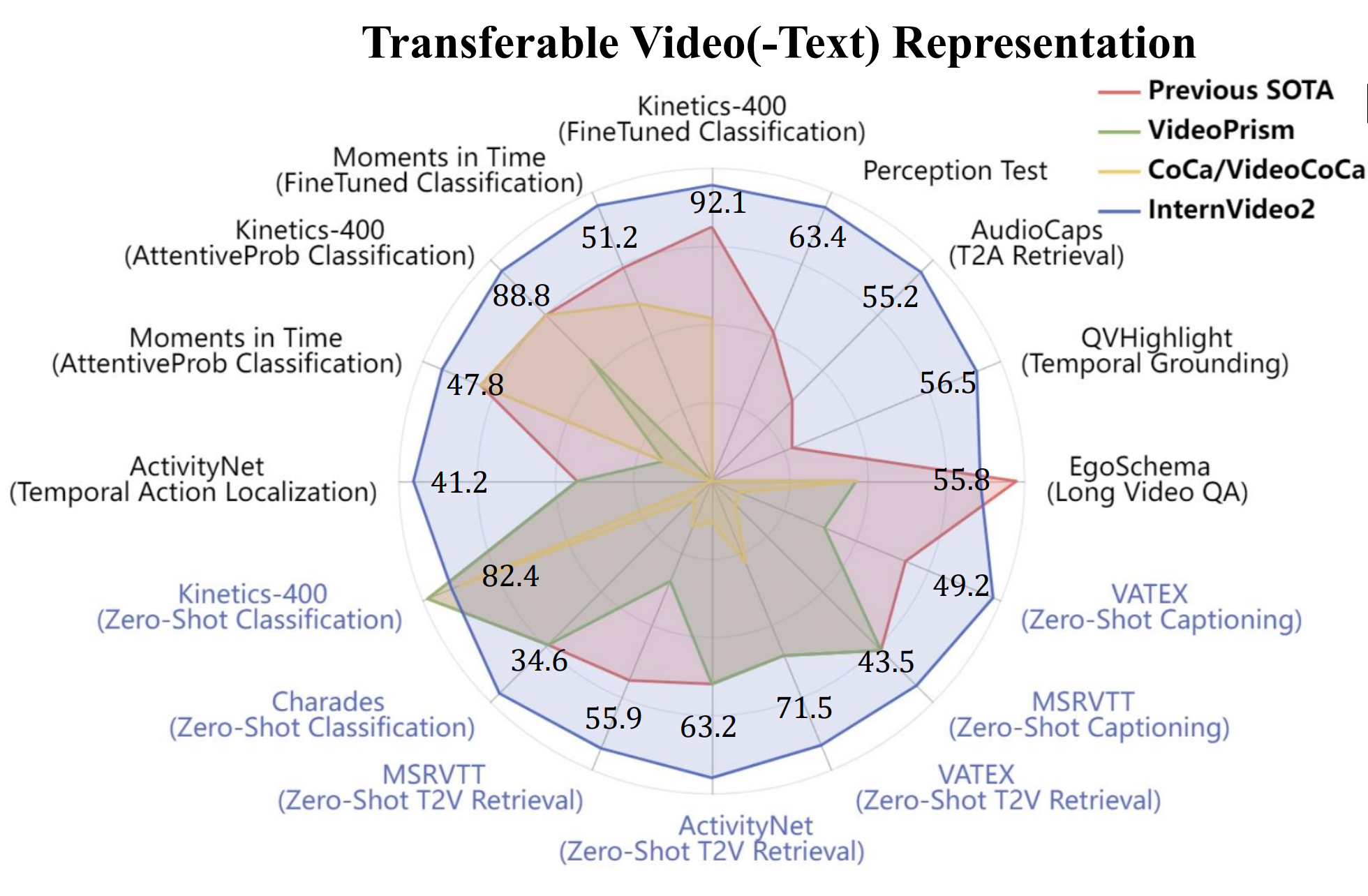
InternVideo2: Scaling Foundation Models for Multimodal Video Understanding. [Paper][Code]
Yi Wang*, Kunchang Li*, Xinhao Li*, Jiashuo Yu*, Yinan He*, Guo Chen, Baoqi Pei, Rongkun Zheng, Jilan Xu, Zun Wang, Yansong Shi, Tianxiang Jiang, SongZe Li, hongjie Zhang, Yifei Huang, Yu Qiao, Yali Wang, Limin Wang (ECCV2024)
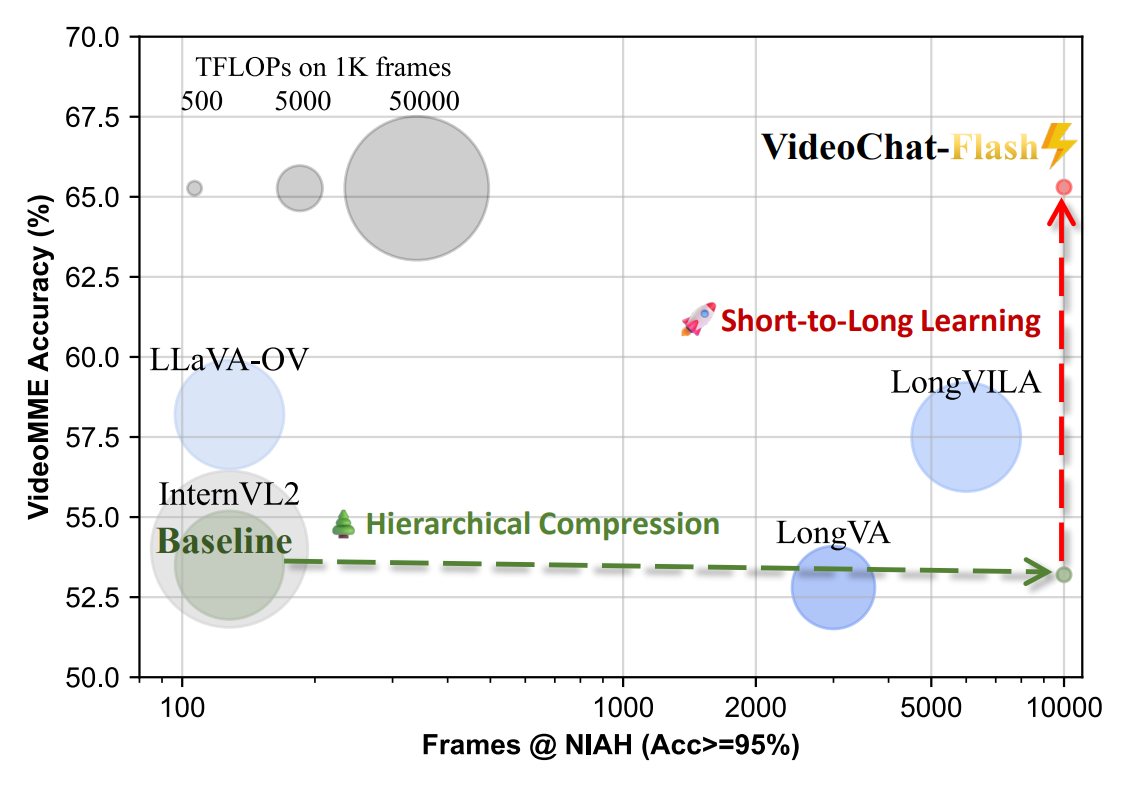
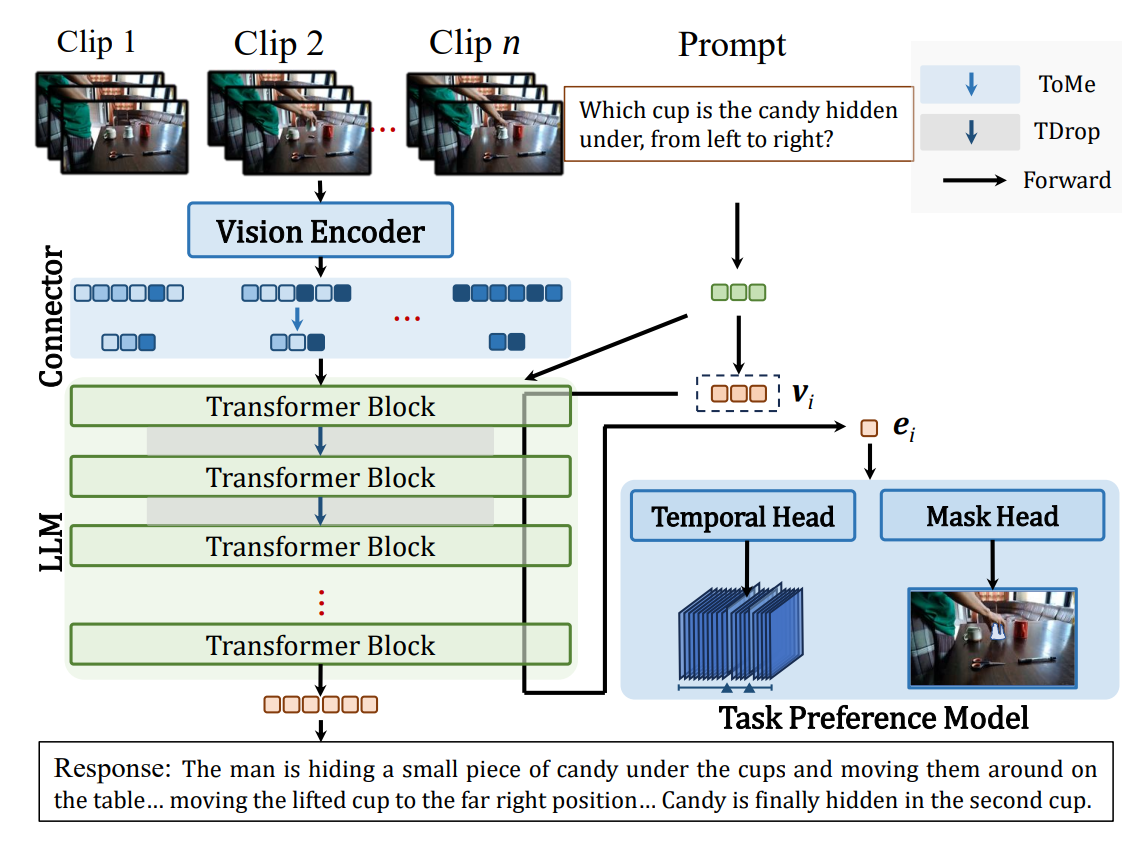
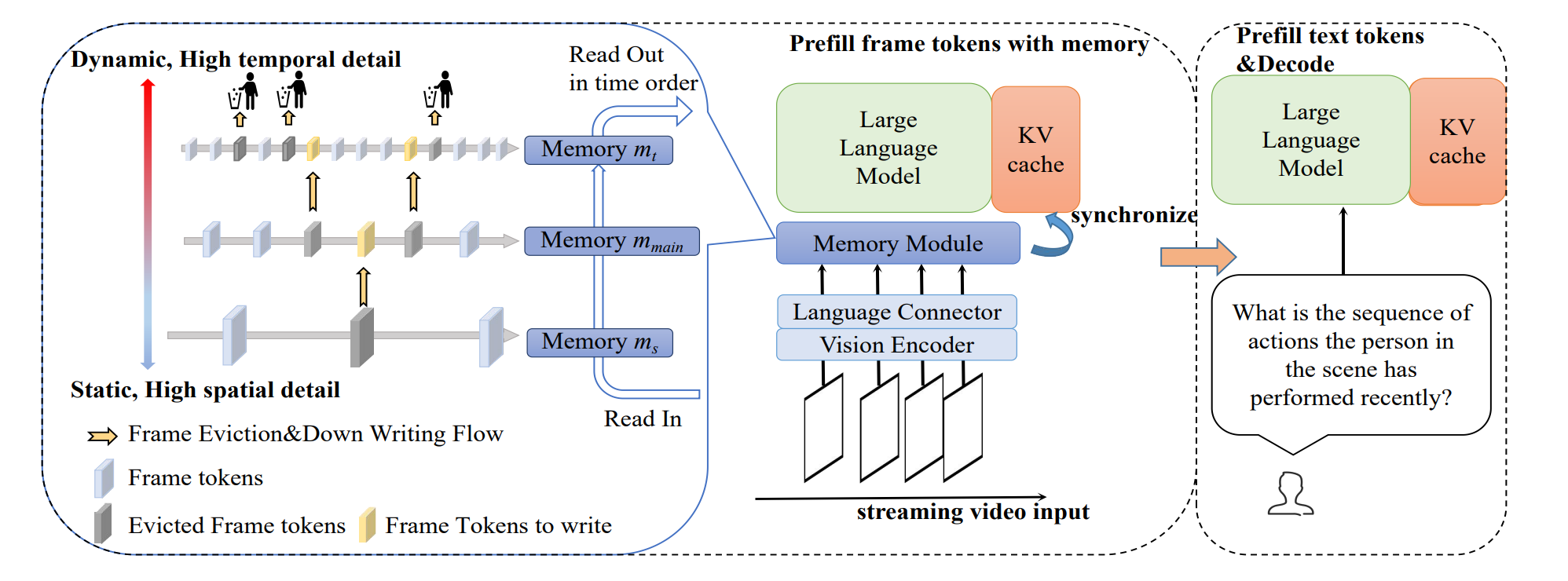
Online Video Understanding: OVBench and VideoChat-Online [Paper]
Zhenpeng Huang*, Xinhao Li*, Jiaqi Li*, Jing Wang, Xiangyu Zeng, Cheng Liang, Tao Wu, Xi Chen, Liang Li, Limin Wang (CVPR2025)
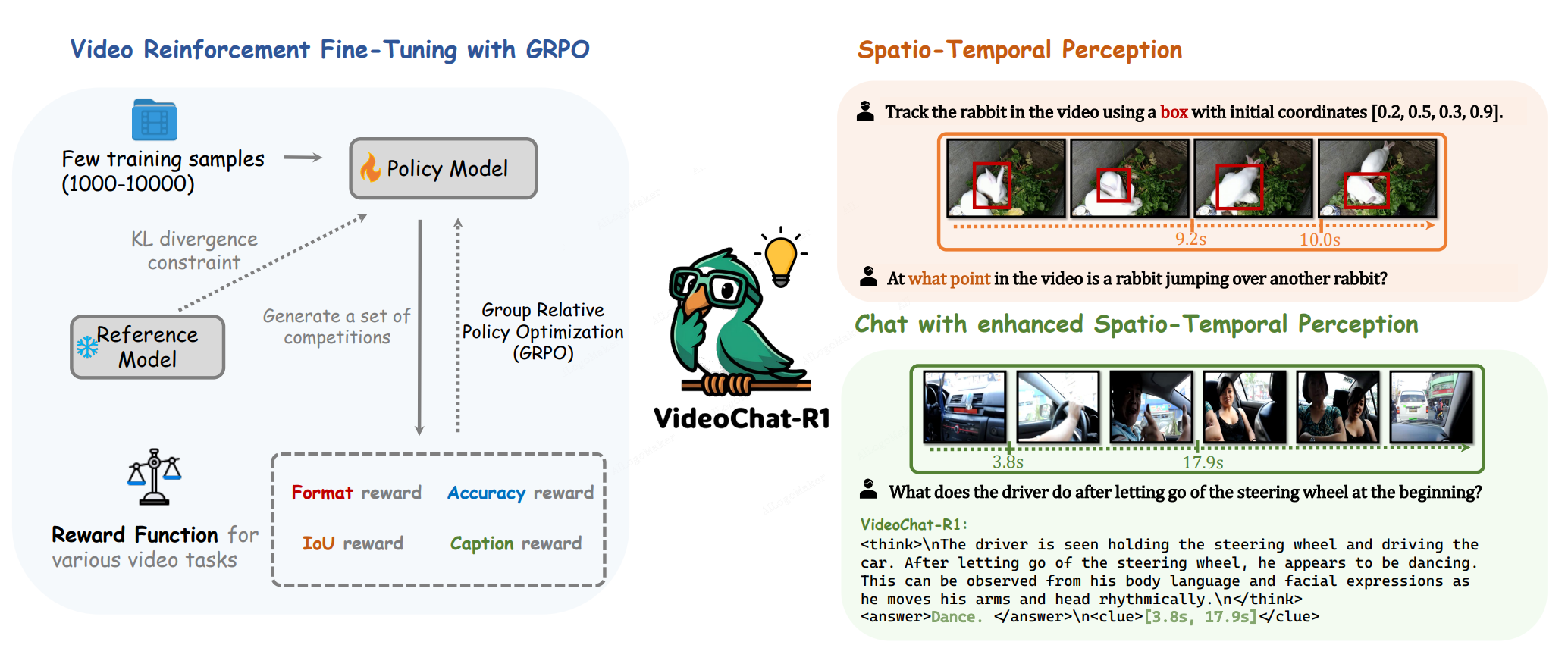
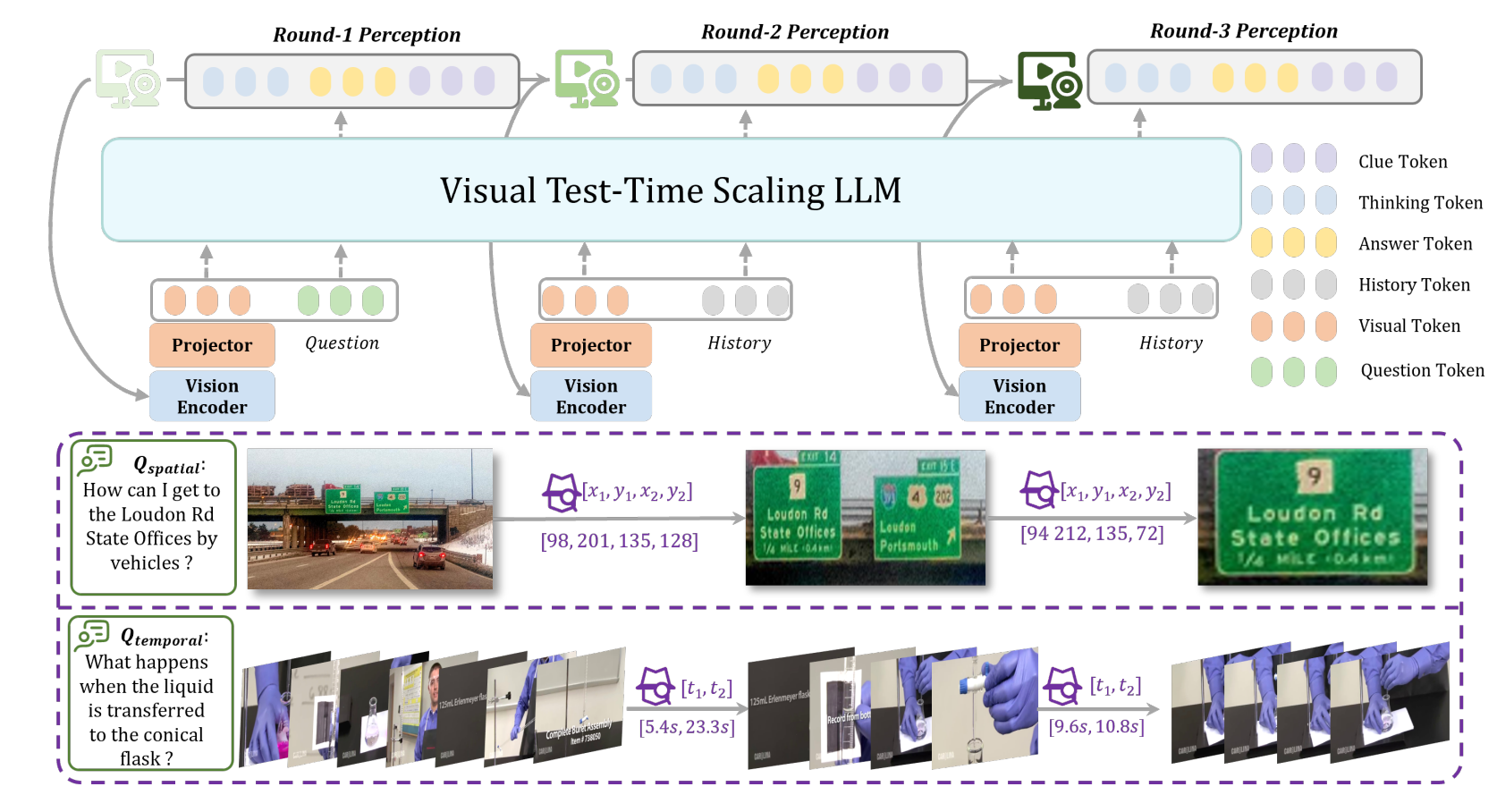
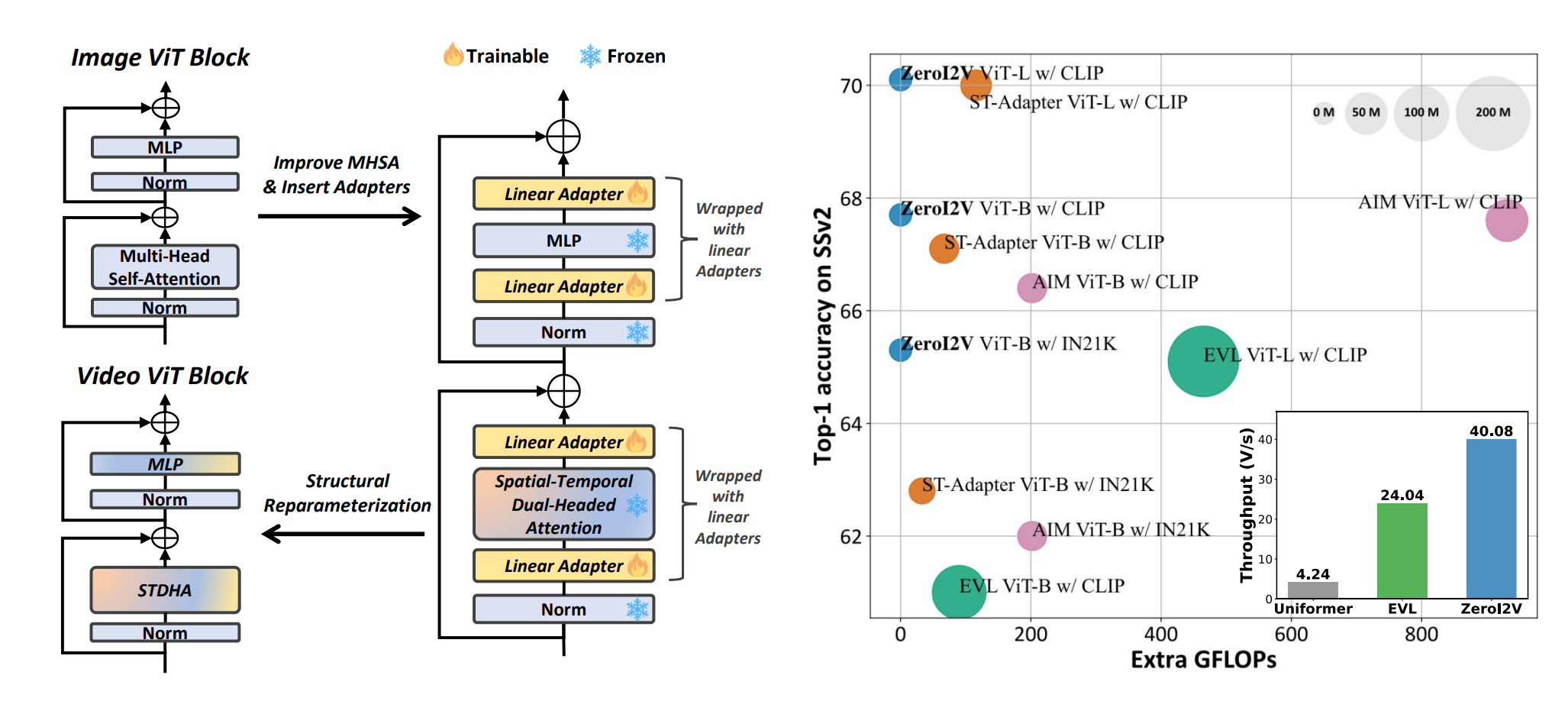
All
See my Google Scholar.